
The latest UK rail safety statistics were published on 17 December 2020, again absent much of the press fanfare we had seen in the past. Regular readers of this blog will know that I have followed the suicide data series, and the press response, closely in 2018, 2017, 2016, 2015, 2014, 2013 and 2012. Last year I missed. By the time I found blogging space around the day job, I felt I had nothing to add. Now again for 2020, I have re-plotted the data myself on a Shewhart chart.

Readers should note the following about the chart.
- Many thanks to Tom Leveson Gower at the Office of Rail and Road who confirmed that the figures are for the year up to the end of March.
- This time, none of the numbers for earlier years have been updated by the statistical authority.
- I have recalculated natural process limits (NPLs) as there are still no more than 20 annual observations. The NPLs have therefore changed but, this year, not by much.
- Again, the pattern of signals, with respect to the NPLs, is similar to last year.
The current chart again shows slightly different signals though nothing surprising. While there is still an observation above the upper NPL in 2015, there is also another one in 2020, and a run of 9 above the centre line from 2012 to 2020, and a run of 8 below from 2002 to 2009. As I always remark, the Terry Weight rule says that a signal gives us license to interpret the ups and downs on the chart. So I shall have a go at doing that.
Despite two successive annual falls in 2016 and 2017 there have now been an increase in the number of fatalities over three consecutive years.
I haven’t yet seen any real contemporaneous comment on the numbers from the Main Stream Media (as we have to call them now, I hear) this year. But what conclusions can we really draw?
Over the last few years, I have been working with the idea that there is a steady increase in the number of suicides. The 2020 data continues to fit that on the linear trend chart. Data points still fall “irregularly” between the trended NPLs.
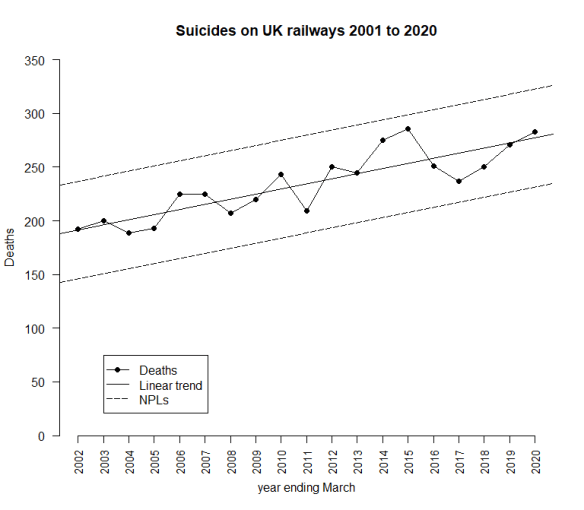
However, when I look at the untrended chart and the 9 points from 2012 to 2020, all consistently above the centre line, I started to think there is an alternative analysis. I have license to interpret the time series but that license carries the obligation to try various interpretations.
An alternative analysis
What about this picture?
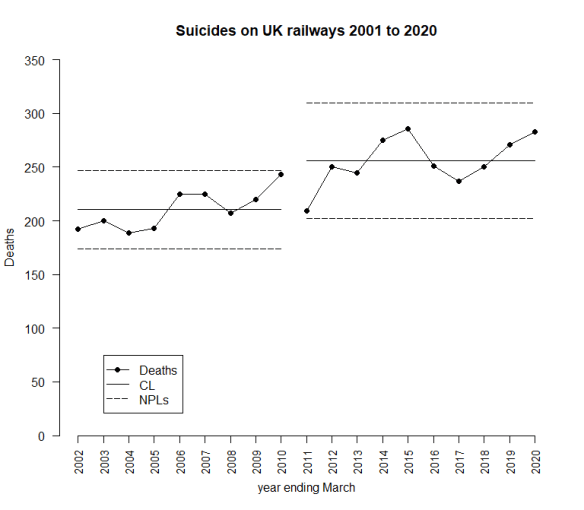
Here, I have stratified the data into two groups: the first 9 observations and the following 10. I have done this just by looking at what the observations suggest. That is permitted because of the Terry Weight rule. Here I have a steady process with a sudden jump around 2010 to 2011 after which the whole thing again becomes steady. That is, in some ways, an attractive picture. It means that deaths have stabilised and are not growing inexorably. But I am looking for an event that happened about 2010 to 2011 that might have led to the jump. I go back to the cause and effect diagram.

Whenever we see a signal we look for its cause. We don’t always find it, or even a candidate. And if at first we don’t succeed we file it away in case it’s elucidated by future data or insight. Knowledge management. I have a suspicion that this is a measurement issue. Why else so signal a step change? But it’s important to watch out for cognitive biases and try to keep an open mind.
A better model?
All models are wrong, but some are useful.
Is this a “better” model than the linear trend? Well if I identified a credible causative event around 2010 it would be. But what about just looking at the data? Is my step change model a “better fit”? One way I can look at this is by comparing residual mean square (“rMS”), a measure of how much “noise” there is after I’ve applied my model. Less noise, better model.
But, before I do the calculation, what about this idea? What if I try putting the break point at 2009/10?
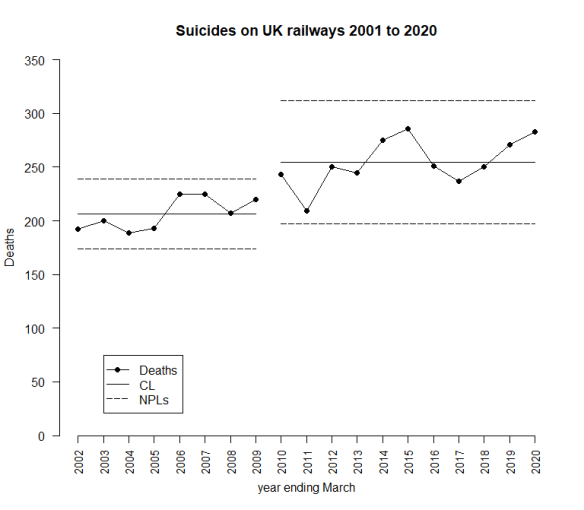
I have no more idea as to why there should be a break point in 2009/10 rather than 2010/11. Which is the better fit? Here are the rMSs.
| Model | rMS (relative units) |
| Linear trend | 255 |
| Break point at 2010 | 433 |
| Break point at 2011 | 298 |
The break-point models don’t look so good from the single stand-point of fitting the data, but they might make more sense with a bit more context. An explanation for the break-point might be compelling as to one model or another. A 2010/11 break point looks a better fit than 2009/10. On the death statistics alone.
I am going to wait until 2021, when I will have 20 observations, before I commit myself. Even then, I reserve the right to go back and change the analysis if future data or insight suggest it. As British mathematician John Maynard Keynes said, “When the facts change, I change my mind – what do you do, sir?”.
Measurement Systems Analysis
I have already suggested here that there may be measurement issues with these numbers. I commented on this back in 2016, in the context of how verdicts of suicides are found in British coroners’ courts. There I noted that coroners could only return a verdict of suicide where they were persuaded of that cause beyond reasonable doubt. I also noted how much that position had been much criticised in the context that findings in the coroners’ courts are generally on the basis of the balance of probabilities, a lower threshold.
In July 2018, an appeal on that point finally reached the High Court who confirmed that verdicts as to suicide ought to be given where the evidence supported the verdict on the balance of probabilities, a less exacting standard than that of beyond reasonable doubt. That decision was confirmed, firstly by the Court of Appeal and then by the Supreme Court of the United Kingdom on 13 November 2020.
That means that there was a definite change in the measurement process in 2018. That ought to go on the chart though, to date, it does not look as though it is reflected in the data. Of course, it only affects the date from the March 2019 statistics onwards. Here is the up to date chart, where I have adopted, purely on the basis of rMS and a prior belief that a step is more likely than a trend, a breakpoint at 2010/11.

 Thus, an activity will in general have two valuable consequences: the physical outputs themselves and the change in information about other activities.
Thus, an activity will in general have two valuable consequences: the physical outputs themselves and the change in information about other activities.




{kind=link}