
This week has seen much soul-searching by the UK polling industry over their performance leading up to the 2015 UK general election on 7 May. The polls had seemed to predict that Conservative and Labour Parties were neck and neck on the popular vote. In the actual election, the Conservatives polled 37.8% to Labour’s 31.2% leading to a working majority in the House of Commons, once the votes were divided among the seats contested. I can assure my readers that it was a shock result. Over breakfast on 7 May I told my wife that the probability of a Conservative majority in the House was nil. I hold my hands up.
An enquiry was set up by the industry led by the National Centre for Research Methods (NCRM). They presented their preliminary findings on 19 January 2016. The principal conclusion was that the failure to predict the voting share was because of biases in the way that the data were sampled and inadequate methods for correcting for those biases. I’m not so sure.
Population -> Frame -> Sample
The first thing students learn when studying statistics is the critical importance, and practical means, of specifying a sampling frame. If the sampling frame is not representative of the population of concern then simply collecting more and more data will not yield a prediction of greater accuracy. The errors associated with the specification of the frame are inherent to the sampling method. Creating a representative frame is very hard in opinion polling because of the difficulty in contacting particular individuals efficiently. It turns out that Conservative voters are harder than Labour voters to get hold of, so that they can be questioned. The NCRM study concluded that, within the commercial constraints of an opinion poll, there was a lower probability that a Conservative voter would be contacted. They therefore tended to be under-represented in the data causing a substantial bias towards Labour.
This is a well known problem in polling practice and there are demographic factors that can be used to make a statistical adjustment. Samples can be stratified. NCRM concluded that, in the run up to the 2015 election, there were important biases tending to under state the Conservative vote and the existing correction factors were inadequate. Fresh sampling strategies were needed to eradicate the bias and improve prediction. There are understandable fears that this will make polling more costly. More calls will be needed to catch Conservatives at home.
Of course, that all sounds an eminently believable narrative. These sorts of sampling frame biases are familiar but enormously troublesome for pollsters. However, I wanted to look at the data myself.
Plot data in time order
That is the starting point of all statistical analysis. Polls continued after the election, though with lesser frequency. I wanted to look at that data after the election in addition to the pre-election data. Here is a plot of poll results against time for Conservative and Labour. I have used data from 25 January to the end of 2015.1, 2 I have not managed to jitter the points so there is some overprinting of Conservative by Labour pre-election.

Now that is an arresting plot. Yet again plotting against time elucidates the cause system. Something happened on the date of the election. Before the election the polls had the two parties neck and neck. The instant (sic) the election was done there was clear red/ blue water between the parties. Applying my (very moderate) level of domain knowledge to the data before, the poll results look stable and predictable. There is a shift after the election to a new datum that remains stable and predictable. The respective arithmetic means are given below.
| Party | Mean Poll Before | Election | Mean Poll After |
| Conservative | 33.3% | 37.8% | 38.8% |
| Labour | 33.5% | 31.2% | 30.9% |
The mean of the post-election polls is doing fairly well but is markedly different from the pre-election results. Now, it is trite statistics that the variation we observe on a chart is the aggregate of variation from two sources.
- Variation from the thing of interest; and
- Variation from the measurement process.
As far as I can gather, the sampling methods used by the polling companies have not so far been modified. They were awaiting the NCRM report. They certainly weren’t modified in the few days following the election. The abrupt change on 7 May cannot be because of corrected sampling methods. The misleading pre-election data and the “impressive” post-election polls were derived from common sampling practices. It seems to me difficult to reconcile NCRM’s narrative to the historical data. The shift in the data certainly needs explanation within that account.
What did change on the election date was that a distant intention turned into the recall of a past action. What everyone wants to know in advance is the result of the election. Unsurprisingly, and as we generally find, it is not possible to sample the future. Pollsters, and their clients, have to be content with individuals’ perceptions of how they will vote. The vast majority of people pay very little attention to politics at all and the general level of interest outside election time is de minimis. Standing in a polling booth with a ballot paper is a very different matter from being asked about intentions some days, weeks or months hence. Most people take voting very seriously. It is not obvious that the same diligence is directed towards answering pollster’s questions.
Perhaps the problems aren’t statistical at all and are more concerned with what psychologists call affective forecasting, predicting how we will feel and behave under future circumstances. Individuals are notoriously susceptible to all sorts of biases and inconsistencies in such forecasts. It must at least be a plausible source of error that intentions are only imperfectly formed in advance and mapping into votes is not straightforward. Is it possible that after the election respondents, once again disengaged from politics, simply recalled how they had voted in May? That would explain the good alignment with actual election results.
Imperfect foresight of voting intention before the election and 20/25 hindsight after is, I think, a narrative that sits well with the data. There is no reason whatever why internal reflections in the Cartesian theatre of future voting should be an unbiased predictor of actual votes. In fact, I think it would be a surprise, and one demanding explanation, if they were so.
The NCRM report does make some limited reference to post-election re-interviews of contacts. However, this is presented in the context of a possible “late swing” rather than affective forecasting. There are no conclusions I can use.
Meta-analysis
The UK polls took a horrible beating when they signally failed to predict the result of the 1992 election in under-estimating the Conservative lead by around 8%.3 Things then felt better. The 1997 election was happier, where Labour led by 13% at the election with final polls in the range of 10 to 18%.4 In 2001 each poll managed to get the Conservative vote within 3% but all over-estimated the Labour vote, some pollsters by as much as 5%.5 In 2005, the final poll had Labour on 38% and Conservative, 33%. The popular vote was Labour 36.2% and Conservative 33.2%.6 In 2010 the final poll had Labour on 29% and Conservative, 36%, with a popular vote of 29.7%/36.9%.7 The debacle of 1992 was all but forgotten when 2015 returned to pundits’ dismay.
Given the history and given the inherent difficulties of sampling and affective forecasting, I’m not sure why we are so surprised when the polls get it wrong. Unfortunately for the election strategist they are all we have. That is a common theme with real world data. Because of its imperfections it has to be interpreted within the context of other sources of evidence rather than followed slavishly. The objective is not to be driven by data but to be led by the insights it yields.
References
- Opinion polling for the 2015 United Kingdom general election. (2016, January 19). In Wikipedia, The Free Encyclopedia. Retrieved 22:57, January 20, 2016, from https://en.wikipedia.org/w/index.php?title=Opinion_polling_for_the_2015_United_Kingdom_general_election&oldid=700601063
- Opinion polling for the next United Kingdom general election. (2016, January 18). In Wikipedia, The Free Encyclopedia. Retrieved 22:55, January 20, 2016, from https://en.wikipedia.org/w/index.php?title=Opinion_polling_for_the_next_United_Kingdom_general_election&oldid=700453899
- Butler, D & Kavanagh, D (1992) The British General Election of 1992, Macmillan, Chapter 7
- — (1997) The British General Election of 1997, Macmillan, Chapter 7
- — (2002) The British General Election of 2001, Palgrave-Macmillan, Chapter 7
- Kavanagh, D & Butler, D (2005) The British General Election of 2005, Palgrave-Macmillan, Chapter 7
- Cowley, P & Kavanagh, D (2010) The British General Election of 2010, Palgrave-Macmillan, Chapter 7
 So Michael Horn, VW’s US CEO has
So Michael Horn, VW’s US CEO has 
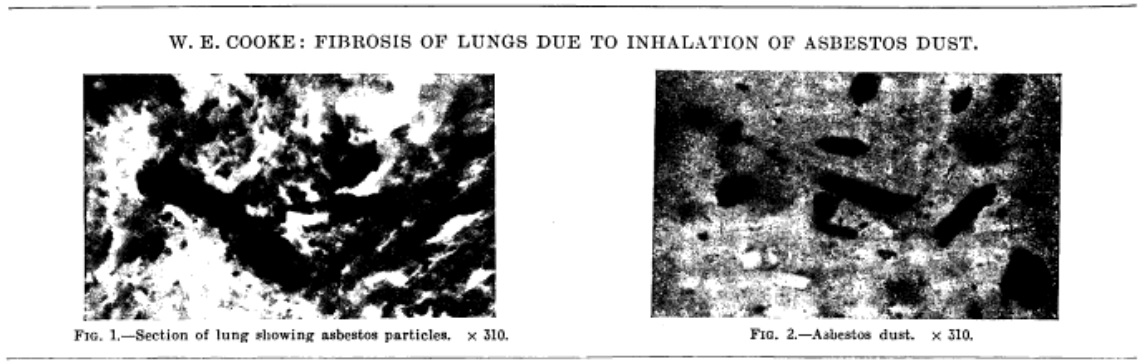

 Smart investigators know that the provenance, reliability and quality of data cannot be taken for granted but must be subject to appropriate scrutiny. The modern science of
Smart investigators know that the provenance, reliability and quality of data cannot be taken for granted but must be subject to appropriate scrutiny. The modern science of 