
Everybody wants to be able to predict the future. Here is the forecaster’s catechism.
- We can do no more that attach a probability to future events.
- Where we have data from an environment that is sufficiently stable to be predictable we can project historical patterns into the future.
- Otherwise, prediction is largely subjective;
- … but there are tactics that can help.
- The Shewhart chart is the tool that helps us know whether we are working with an environment that is sufficiently stable to be predictable.
Now let’s get to work.
What does a stable/ predictable environment look like?
Every trial lawyer knows the importance of constructing a narrative out of evidence, an internally consistent and compelling arrangement of the facts that asserts itself above competing explanations. Time is central to how a narrative evolves. It is time that suggests causes and effects, motivations, barriers and enablers, states of knowledge, external influences, sensitisers and cofactors. That’s why exploration of data always starts with plotting it in time order. Always.
Let’s start off by looking at something we know to be predictable. Imagine a bucket of thousands of spherical beads. Of the beads, 80% are white and 20%, red. You are given a paddle that will hold 50 beads. Use the paddle to stir the beads then draw out 50 with the paddle. Count the red beads. Now you may, at this stage, object. Surely, this is just random and inherently unpredictable. But I want to persuade you that this is the most predictable data you have ever seen. Let’s look at some data from 20 sequential draws. In time order, of course, in Fig. 1.
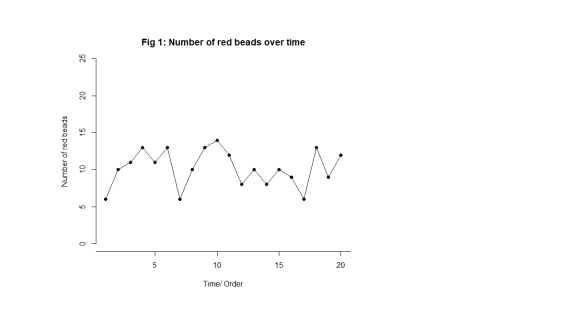
Just to look at the data from another angle, always a good idea, I have added up how many times a particular value, 9, 10, 11, … , turns up and tallied them on the right hand side. For example, here is the tally for 12 beads in Fig. 2.

We get this in Fig. 3.

Here are the important features of the data.
- We can’t predict what the exact value will be on any particular draw.
- The numbers vary irregularly from draw to draw, as far as we can see.
- We can say that draws will vary somewhere between 2 (say) and 19 (say).
- Most of the draws are fairly near 10.
- Draws near 2 and 19 are much rarer.
I would be happy to predict that the 21st draw will be between 2 and 19, probably not too far from 10. I have tried to capture that in Fig. 4. There are limits to variation suggested by the experience base. As predictions go, let me promise you, that is as good as it gets.
Even statistical theory would point to an outcome not so very different from that. That theoretical support adds to my confidence.

But there’s something else. Something profound.
A philosopher, an engineer and a statistician walk into a bar …
… and agree.
I got my last three bullet points above from just looking at the tally on the right hand side. What about the time order I was so insistent on preserving? As Daniel Kahneman put it “A random event does not … lend itself to explanation, but collections of random events do behave in a highly regular fashion.” What is this “regularity” when we can see how irregularly the draws vary? This is where time and narrative make their appearance.
If we take the draw data above, the exact same data, and “shuffle” it into a fresh order, we get this, Fig. 5.

Now the bullet points still apply to the new arrangement. The story, the narrative, has not changed. We still see the “irregular” variation. That is its “regularity”, that is tells the same story when we shuffle it. The picture and its inferences are the same. We cannot predict an exact value on any future draw yet it is all but sure to be between 2 and 19 and probably quite close to 10.
In 1924, British philosopher W E Johnson and US engineer Walter Shewhart, independently, realised that this was the key to describing a predicable process. It shows the same “regular irregularity”, or shall we say stable irregularity, when you shuffle it. Italian statistician Bruno de Finetti went on to derive the rigorous mathematics a few years later with his famous representation theorem. The most important theorem in the whole of statistics.
This is the exact characterisation of noise. If you shuffle it, it makes no difference to what you see or the conclusions you draw. It makes no difference to the narrative you construct (sic). Paradoxically, it is noise that is predictable.
To understand this, let’s look at some data that isn’t just noise.
Events, dear boy, events.
That was the alleged response of British Prime Minister Harold Macmillan when asked what had been the most difficult aspect of governing Britain.
Suppose our data looks like this in Fig. 6.

Let’s make it more interesting. Suppose we are looking at the net approval rating of a politician (Fig. 7).
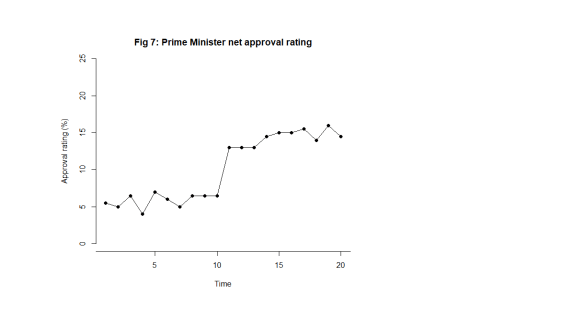
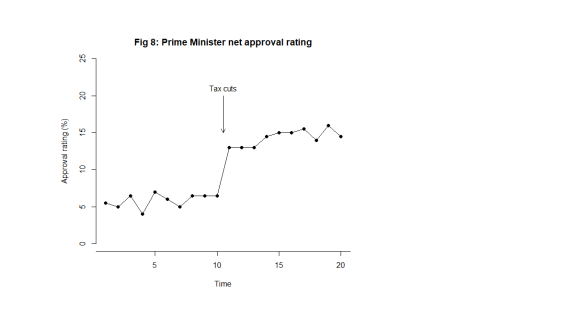
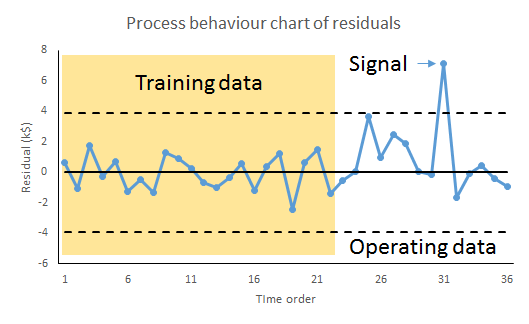
What this looks like is noise plus a material step change between the 10th and 11th observation. Now, this is a surprise. The regularity, and the predictability, is broken. In fact, my first reaction is to ask What happened? I research political events and find at that same time there was an announcement of universal tax cuts (Fig. 8). This is just fiction of course. That then correlates with the shift in the data I observe. The shift is a signal, a flag from the data telling me that something happened, that the stable irregularity has become an unstable irregularity. I use the time context to identify possible explanations. I come up with the tentative idea about tax cuts as an explanation of the sudden increase in popularity.
The bullet points above no longer apply. The most important feature of the data now is the shift, I say, caused by the Prime Minister’s intervention.
What happens when I shuffle the data into a random order though (Fig. 9)?
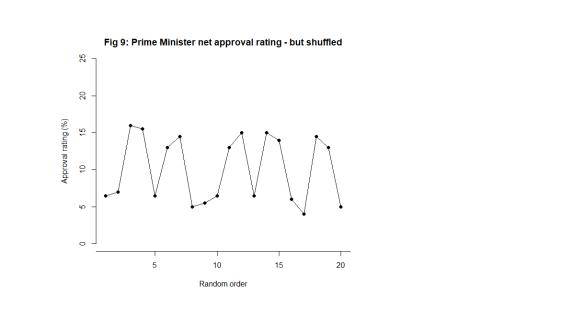
Now, the signal is distorted, hard to see and impossible to localise in time. I cannot tie it to a context. The message in the data is entirely different. The information in the chart is not preserved. The shuffled data does not bear the same narrative as the time ordered data. It does not tell the same story. It does not look the same. That is how I know there is a signal. The data changes its story when shuffled. The time order is crucial.
Of course, if I repeated the tally exercise that I did on Fig. 4, the tally would look the same, just as it did in the noise case in Fig. 5.
Is data with signals predictable?
The Prime Minister will say that they predicted that their tax cuts would be popular and they probably did so. My response to that would be to ask how big an improvement they predicted. While a response in the polls may have been foreseeable, specifying its magnitude is much more difficult and unlikely to be exact.
We might say that the approval data following the announcement has returned to stability. Can we not now predict the future polls? Perhaps tentatively in the short term but we know that “events” will continue to happen. Not all these will be planned by the government. Some government initiatives, triumphs and embarrassments will not register with the public. The public has other things to be interested in. Here is some UK data.
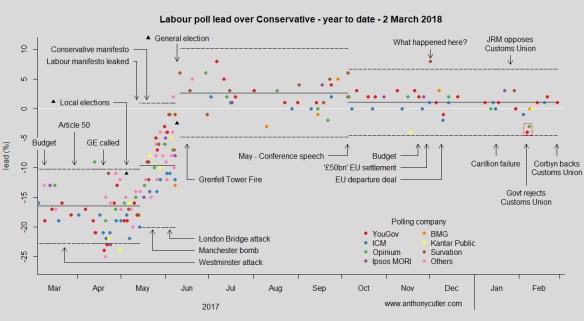
You can follow regular updates here if you are interested.
Shewhart’s ingenious chart
While Johnson and de Finetti were content with theory, Shewhart, working in the manufacture of telegraphy equipment, wanted a practical tool for his colleagues that would help them answer the question of predictability. A tool that would help users decide whether they were working with an environment sufficiently stable to be predictable. Moreover, he wanted a tool that would be easy to use by people who were short of time time for analysing data and had minds occupied by the usual distractions of the work place. He didn’t want people to have to run off to a statistician whenever they were perplexed by events.
In Part 2 I shall start to discuss how to construct Shewhart’s chart. In subsequent parts, I shall show you how to use it.



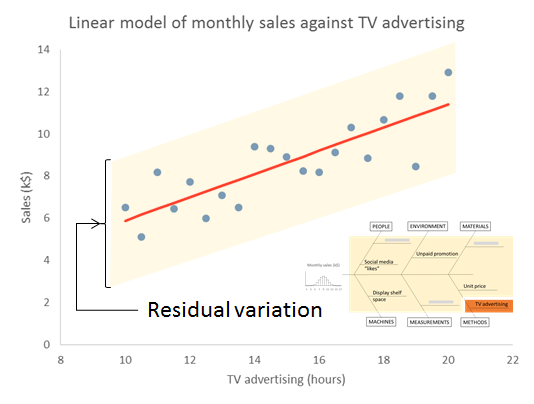


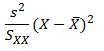
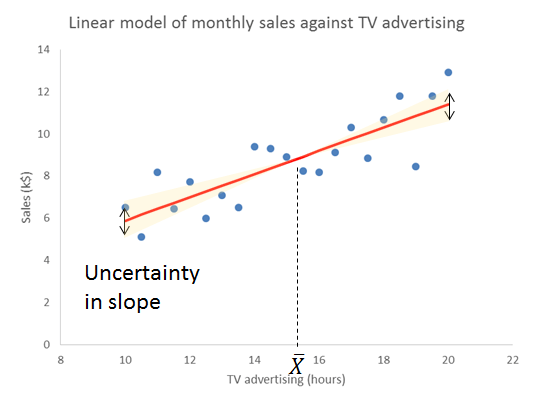


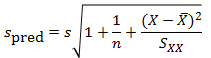
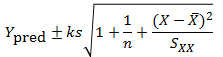
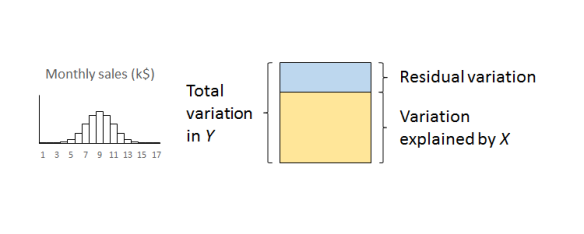
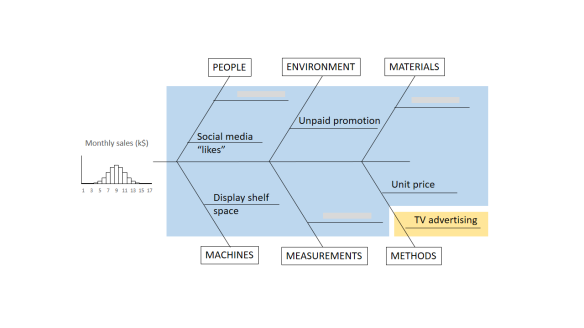
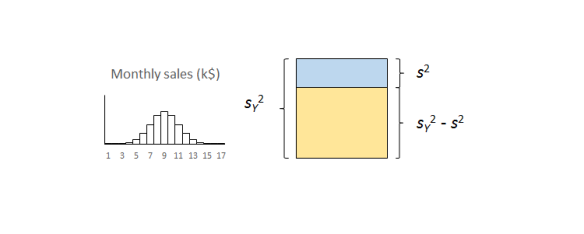
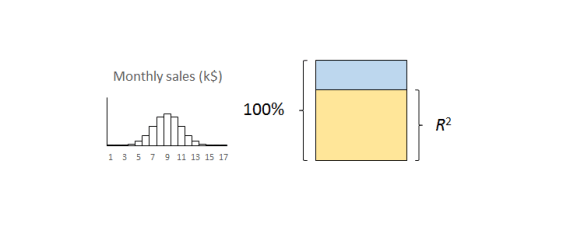 The important thing to remember is that the residual variation is not a statistical artifact of the analysis. It is part of the real world business system, the cause-system of the Ys.7 It is the part on which you still have little quantitative grasp and which continues to hurt you. Returning to the cause and effect diagram, we picked one factor X to investigate and took its influence out of the data. The residual variation is the variation arising from the aggregate of all the other causes.
The important thing to remember is that the residual variation is not a statistical artifact of the analysis. It is part of the real world business system, the cause-system of the Ys.7 It is the part on which you still have little quantitative grasp and which continues to hurt you. Returning to the cause and effect diagram, we picked one factor X to investigate and took its influence out of the data. The residual variation is the variation arising from the aggregate of all the other causes.