
Time for The Guardian to get the bad data-journalism award for this headline (25 February 2019).
Vaccine scepticism grows in line with rise of populism – study
Surges in measles cases map tightly to countries where populism is on the march
The report was a journalistic account of a paper by Jonathan Kennedy of the Global Health Unit, Centre for Primary Care and Public Health, Barts and the London School of Medicine and Dentistry, Queen Mary University of London, entitled Populist politics and vaccine hesitancy in Western Europe: an analysis of national-level data.1
Studies show a strong correlation between votes for populist parties and doubts that vaccines work, declared the newspaper, relying on support from the following single chart redrawn by The Guardian‘s own journalists.

It seemed to me there was more to the chart than the newspaper report. Is it possible this was all based on an uncritical regression line? Like this (hand drawn line but, believe me, it barely matters – you get the idea).
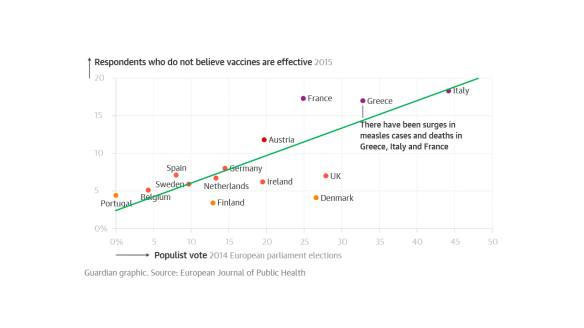
Perhaps there was a p-value too but I shall come back to that. However, looking back at the raw chart, I wondered if it wouldn’t bear a different analysis. The 10 countries, Portugal, …, Denmark and the UK all have “vaccine hesitancy” rates around 6%. That does not vary much with populist support varying between 0% and 27% between them. Again, France, Greece and Germany all have “hesitancy” rates of around 17%, such rate not varying much with populist support varying from 25% to 45%. In fact the Guardian journalist seems to have had that though too. The two groups are colour coded on the chart. So much for the relationship between “populism” and “vaccine hesitancy”. Austria seems not to fit into either group but perhaps that makes it interesting. France has three times the hesitancy of Denmark but is less “populist”.
So what about this picture?

Perhaps there are two groups, one with “hesitancy” around 6% and one, around 17%. Austria is an interesting exception. What differences are there between the two groups, aside from populist sentiment? I don’t know because it’s not my study or my domain of knowledge. But, whenever there is a contrast between two groups we ought to explore all the differences we can think of before putting forward an, even tentative, explanation. That’s what Ignaz Semmelweis did when he observed signal differences in post-natal mortality between two wards of the Vienna General Hospital in the 1840s.2 Austria again, coincidentally. He investigated all the differences that he could think of between the wards before advancing and testing his theory of infection. As to the vaccine analysis, we already suspect that there are particular dynamics in Italy around trust in bureaucracy. That’s where the food scare over hormone-treated beef seems to have started so there may be forces at work that make it atypical of the other countries.3, 4, 5
Slightly frustrated, I decided that I wanted to look at the original publication. This was available free of charge on the publisher’s website at the time I read The Guardian article. But now it isn’t. You will have to pay EUR 36, GBP 28 or USD 45 for 24 hour access. Perhaps you feel you already paid.
The academic research
The “populism” data comes from votes cast in the 2014 elections to the European Parliament. That means that the sampling frame was voters in that election. Turnout in the election was 42%. That is not the whole of the population of the respective countries and voters at EU elections are, I think I can safely say, are not representative of the population at large. The “hesitancy” data came from something called the Vaccine Confidence Project (“the VCP”) for which citations are given. It turns out that 65,819 individuals were sampled across 67 countries in 2015. I have not looked at details of the frame, sampling, handling of non-responses, adjustments and so on, but I start off by noting that the two variables are sampled from, inevitably, different frames and that is not really discussed in the paper. Of course here, We make no mockery of honest ad-hockery.6
The VCP put a number of questions to the respondents. It is not clear from the paper whether there were more questions than analysed here. Each question was answered “strongly agree”, “tend to agree”, “do not know”, “tend to disagree”, and “strongly disagree”. The “hesitancy” variable comes from the aggregate of the latter two categories. I would like to have seen the raw data.
The three questions are set out below, along with the associated R2s from the regression analysis.
| Question | R2 |
| (1) Vaccines are important for children to have | 63% |
| (2) Overall I think vaccines are effective | 52% |
| (3) Overall I think vaccines are safe. | 25% |
Well the individual questions raise issues about variation in interpreting the respective meanings, notwithstanding translation issues between languages, fidelity and felicity.
As I guessed, there were p-values but, as usual, they add nil to the analysis.
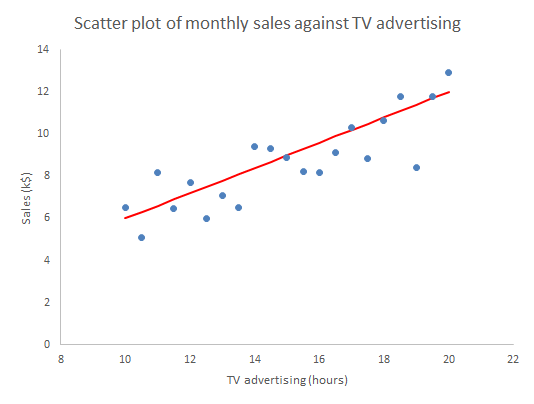
We now see that the plot reproduced in The Guardian is for question (2) alone and has R2 = 52%. I would have been interested in seeing R2 for my 2-level analysis. The plotted response for question (1) (not reproduced here) actually looks a bit more like a straight line and has better fit. However, in both cases, I am worried by how much leverage the Italy group has. Not discussed in the paper. No regression diagnostics.
So how about this picture, from Kennedy’s paper, for the response to question (3)?

Now, the variation in perceptions of vaccine safety, between France, Greece and Italy, is greater than between the remainder countries. Moreover, if anything, among that group, there is evidence that “hesitancy” falls as “populism” increases. There is certainly no evidence that it increases. In my opinion, that figure is powerful evidence that there are other important factors at work here. That is confirmed by the lousy R2 = 25% for the regression. And this is about perceptions of vaccine safety specifically.
I think that the paper also suffers from a failure to honour John Tukey’s trenchant distinction between exploratory data analysis and confirmatory data analysis. Such a failure always leads to trouble.
Confirmation bias
On the basis of his analysis, Kennedy felt confident to conclude as follows.
Vaccine hesitancy and political populism are driven by similar dynamics: a profound distrust in elites and experts. It is necessary for public health scholars and actors to work to build trust with parents that are reluctant to vaccinate their children, but there are limits to this strategy. The more general popular distrust of elites and experts which informs vaccine hesitancy will be difficult to resolve unless its underlying causes—the political disenfranchisement and economic marginalisation of large parts of the Western European population—are also addressed.
Well, in my opinion that goes a long way from what the data reveal. The data are far from from being conclusive as to association between “vaccine hesitancy” and “populism”. Then there is the unsupported assertion of a common causation in “political disenfranchisement and economic marginalisation”. While the focus remains there, the diligent search for other important factors is ignored and devalued.
We all suffer from a confirmation bias in favour of our own cherished narratives.7 We tend to believe and share evidence that we feel supports the narrative and ignore and criticise that which doesn’t. That has been particularly apparent over recent months in the energetic, even enthusiastic, reporting as fact of the scandalous accusations made against Nathan Phillips and dubious allegations made by Jussie Smollett. They fitted a narrative.
I am as bad. I hold to the narrative that people aren’t very good with statistics and constantly look for examples that I can dissect to “prove” that. Please tell me when you think I get it wrong.
Yet, it does seem to me the that the author here, and The Guardian journalist, ought to have been much more critical of the data and much more curious as to the factors at work. In my view, The Guardian had a particular duty of candour as the original research is not generally available to the public.
This sort of selective analysis does not build trust in “elites and experts”.
References
- Kennedy, J (2019) Populist politics and vaccine hesitancy in Western Europe: an analysis of national-level data, Journal of Public Health, ckz004, https://doi.org/10.1093/eurpub/ckz004
- Semmelweis, I (1860) The Etiology, Concept, and Prophylaxis of Childbed Fever, trans. K Codell Carter [1983] University of Wisconsin Press: Madison, Wisconsin
- Kerr, W A & Hobbs, J E (2005). “9. Consumers, Cows and Carousels: Why the Dispute over Beef Hormones is Far More Important than its Commercial Value”, in Perdikis, N & Read, R, The WTO and the Regulation of International Trade. Edward Elgar Publishing, pp 191–214
- Caduff, L (August 2002). “Growth Hormones and Beyond” (PDF). ETH Zentrum. Archived from the original (PDF) on 25 May 2005. Retrieved 11 December 2007.
- Gandhi, R & Snedeker, S M (June 2000). “Consumer Concerns About Hormones in Food“. Program on Breast Cancer and Environmental Risk Factors. Cornell University. Archived from the original on 19 July 2011.
- I J Good
- Kahneman, D (2011) Thinking, Fast and Slow, London: Allen Lane, pp80-81
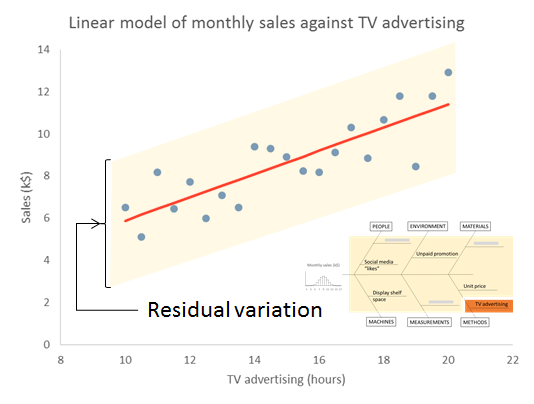


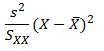
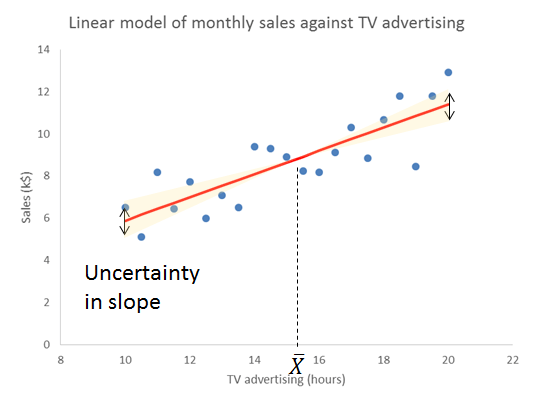


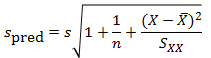
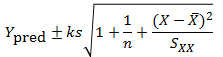
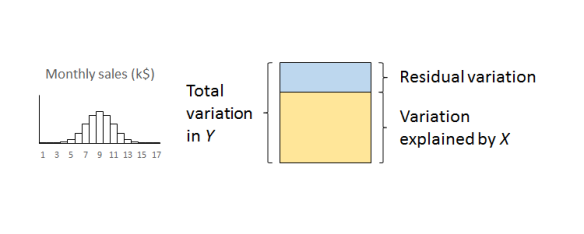
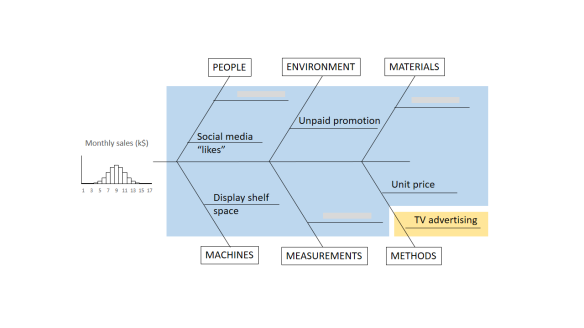
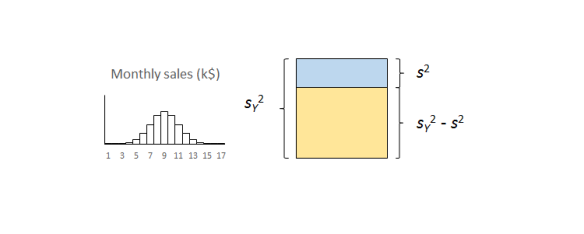
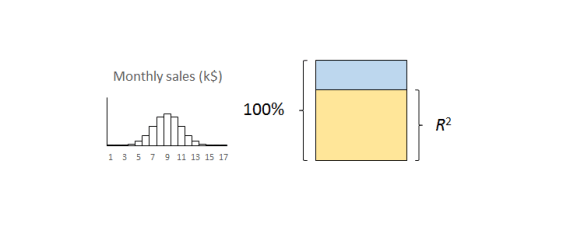 The important thing to remember is that the residual variation is not a statistical artifact of the analysis. It is part of the real world business system, the cause-system of the Ys.7 It is the part on which you still have little quantitative grasp and which continues to hurt you. Returning to the cause and effect diagram, we picked one factor X to investigate and took its influence out of the data. The residual variation is the variation arising from the aggregate of all the other causes.
The important thing to remember is that the residual variation is not a statistical artifact of the analysis. It is part of the real world business system, the cause-system of the Ys.7 It is the part on which you still have little quantitative grasp and which continues to hurt you. Returning to the cause and effect diagram, we picked one factor X to investigate and took its influence out of the data. The residual variation is the variation arising from the aggregate of all the other causes.




 “A new study has unearthed some eye-opening facts about the effects of noise pollution on obesity,”
“A new study has unearthed some eye-opening facts about the effects of noise pollution on obesity,” 
