I recently saw an article in the Harvard Business Review called “Refresher on Regression Analysis”. I thought it was horrible so I wanted to set the record straight.
Linear regression from the viewpoint of machine learning
Linear regression is important, not only because it is a useful tool in itself, but because it is (almost) the simplest statistical model. The issues that arise in a relatively straightforward form are issues that beset the whole of statistical modelling and predictive analytics. Anyone who understands linear regression properly is able to ask probing questions about more complicated models. The complex internal algorithms of Kalman filters, ARIMA processes and artificial neural networks are accessible only to the specialist mathematician. However, each has several general features in common with simple linear regression. A thorough understanding of linear regression enables a due diligence of the claims made by the machine learning advocate. Linear regression is the paradigmatic exemplar of machine learning.
There are two principal questions that I want to talk about that are the big takeaways of linear regression. They are always the first two questions to ask in looking at any statistical modelling or machine learning scenario.
- What predictions can I make (if any)?
- Is it worth the trouble?
I am going to start looking at (1) in this blog and complete it in a future Part 2. I will then look at (2) in a further Part 3.
Variation, variation, variation
Variation is a major problem for business, the tendency of key measures to fluctuate irregularly. Variation leads to uncertainty. Will the next report be high or low? Or in the middle? Because of the uncertainty we have to allow safety margins or swallow some non-conformancies. We have good days and bad days, good products and not so good. We have to carry costly working capital because of variation in cash flow. And so on.
We learned in our high school statistics class to characterise variation in a key process measure, call it the Big Y, by an histogram of observations. Perhaps we are bothered by the fluctuating level of monthly sales.

The variation arises from a whole ecology of competing and interacting effects and factors that we call the cause-system of the outcome. In general, it is very difficult to single out individual factors as having been the cause of a particular observation, so entangled are they. It is still useful to capture them for reference on a cause and effect diagram.

One of the strengths of the cause and effect diagram is that it may prompt the thought that one of the factors is particularly important, call it Big X, perhaps it is “hours of TV advertising” (my age is showing). Motivated by that we can generate a sample of corresponding measurements data of both the Y and X and plot them on a scatter plot.

Well what else is there to say? The scatter plot shows us all the information in the sample. Scatter plots are an important part of what statistician John Tukey called Exploratory Data Analysis (EDA). We have some hunches and ideas, or perhaps hardly any idea at all, and we attack the problem by plotting the data in any way we can think of. So much easier now than when W Edwards Deming wrote:1
[Statistical practice] means tedious work, such as studying the data in various forms, making tables and charts and re-making them, trying to use and preserve the evidence in the results and to be clear enough to the reader: to endure disappointment and discouragement.
Or as Chicago economist Ronald Coase put it.
If you torture the data enough, nature will always confess.
The scatter plot is a fearsome instrument of data torture. It tells me everything. It might even tempt me to think that I have a basis on which to make predictions.
Prediction
In machine learning terms, we can think of the sample used for the scatter plot as a training set of data. It can be used to set up, “train”, a numerical model that we will then fix and use to predict future outcomes. The scatter plot strongly suggests that if we know a future X alone we can have a go at predicting the corresponding future Y. To see that more clearly we can draw a straight line by hand on the scatter plot, just as we did in high school before anybody suggested anything more sophisticated.
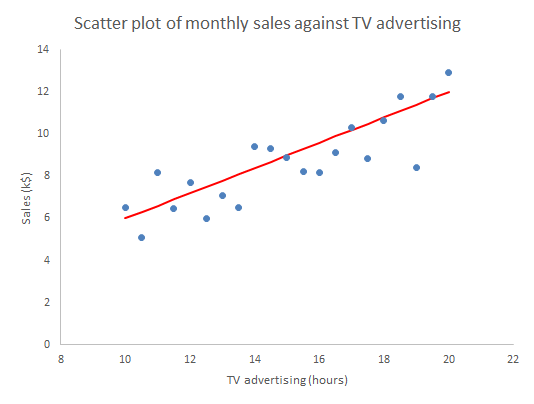
Given any particular X we can read off the corresponding Y.

The immediate insight that comes from drawing in the line is that not all the observations lie on the line. There is variation about the line so that there is actually a range of values of Y that seem plausible and consistent for any specified X. More on that in Parts 2 and 3.
In understanding machine learning it makes sense to start by thinking about human learning. Psychologists Gary Klein and Daniel Kahneman investigated how firefighters were able to perform so successfully in assessing a fire scene and making rapid, safety critical decisions. Lives of the public and of other firefighters were at stake. This is the sort of human learning situation that machines, or rather their expert engineers, aspire to emulate. Together, Klein and Kahneman set out to describe how the brain could build up reliable memories that would be activated in the future, even in the agony of the moment. They came to the conclusion that there are two fundamental conditions for a human to acquire a skill.2
- An environment that is sufficiently regular to be predictable.
- An opportunity to learn these regularities through prolonged practice
The first bullet point is pretty much the most important idea in the whole of statistics. Before we can make any prediction from the regression, we have to be confident that the data has been sampled from “an environment that is sufficiently regular to be predictable”. The regression “learns” from those regularities, where they exist. The “learning” turns out to be the rather prosaic mechanics of matrix algebra as set out in all the standard texts.3 But that, after all, is what all machine “learning” is really about.
Statisticians capture the psychologists’ “sufficiently regular” through the mathematical concept of exchangeability. If a process is exchangeable then we can assume that the distribution of events in the future will be like the past. We can project our historic histogram forward. With regression we can do better than that.
Residuals analysis
Formally, the linear regression calculations calculate the characteristics of the model:
Y = mX + c + “stuff”
The “mX+c” bit is the familiar high school mathematics equation for a straight line. The “stuff” is variation about the straight line. What the linear regression mathematics does is (objectively) to calculate the m and c and then also tell us something about the “stuff”. It splits the variation in Y into two components:
- What can be explained by the variation in X; and
- The, as yet unexplained, variation in the “stuff”.
The first thing to learn about regression is that it is the “stuff” that is the interesting bit. In 1849 British astronomer Sir John Herschel observed that:
Almost all the greatest discoveries in astronomy have resulted from the consideration of what we have elsewhere termed RESIDUAL PHENOMENA, of a quantitative or numerical kind, that is to say, of such portions of the numerical or quantitative results of observation as remain outstanding and unaccounted for after subducting and allowing for all that would result from the strict application of known principles.
The straight line represents what we guessed about the causes of variation in Y and which the scatter plot confirmed. The “stuff” represents the causes of variation that we failed to identify and that continue to limit our ability to predict and manage. We call the predicted Ys that correspond to the measured Xs, and lie on the fitted straight line, the fits.
fiti = mXi + c
The residual values, or residuals, are obtained by subtracting the fits from the respective observed Y values. The residuals represent the “stuff”. Statistical software does this for us routinely. If yours doesn’t then bin it.
residuali = Yi – fiti

There are a number of properties that the residuals need to satisfy for the regression to work. Investigating those properties is called residuals analysis.4 As far as use for prediction in concerned, it is sufficient that the “stuff”, the variation about the straight line, be exchangeable.5 That means that the “stuff” so far must appear from the data to be exchangeable and further that we have a rational belief that such a cause system will continue unchanged into the future. Shewhart charts are the best heuristics for checking the requirement for exchangeability, certainly as far as the historical data is concerned. Our first and, be under no illusion, mandatory check on the ability of the linear regression, or any statistical model, to make predictions is to plot the residuals against time on a Shewhart chart.
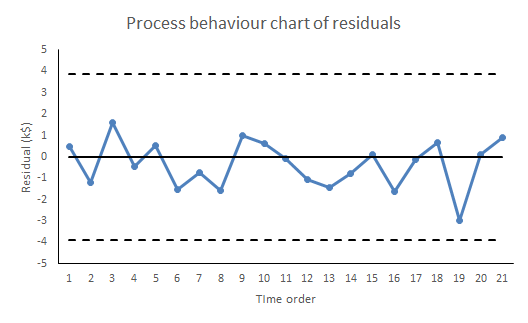
If there are any signals of special causes then the model cannot be used for prediction. It just can’t. For prediction we need residuals that are all noise and no signal. However, like all signals of special causes, such will provide an opportunity to explore and understand more about the cause system. The signal that prevents us from using this regression for prediction may be the very thing that enables an investigation leading to a superior model, able to predict more exactly than we ever hoped the failed model could. And even if there is sufficient evidence of exchangeability from the training data, we still need to continue vigilance and scrutiny of all future residuals to look out for any novel signals of special causes. Special causes that arise post-training provide fresh information about the cause system while at the same time compromising the reliability of the predictions.
Thorough regression diagnostics will also be able to identify issues such as serial correlation, lack of fit, leverage and heteroscedasticity. It is essential to regression and its ommision is intolerable. Residuals analysis is one of Stephen Stigler’s Seven Pillars of Statistical Wisdom.6 As Tukey said:
The greatest value of a picture is when it forces us to notice what we never expected to see.
To come:
Part 2: Is my regression significant? … is a dumb question.
Part 3: Quantifying predictions with statistical intervals.
References
- Deming, W E (1975) “On probability as a basis for action”, The American Statistician 29(4) pp146-152
- Kahneman, D (2011) Thinking, Fast and Slow, Allen Lane, p240
- Draper, N R & Smith, H (1998) Applied Regression Analysis, 3rd ed., Wiley, p44
- Draper & Smith (1998) Chs 2, 8
- I have to admit that weaker conditions may be adequate in some cases but these are far beyond any other than a specialist mathematician.
- Stigler, S M (2016) The Seven Pillars of Statistical Wisdom, Harvard University Press, Chapter 7
 “A new study has unearthed some eye-opening facts about the effects of noise pollution on obesity,”
“A new study has unearthed some eye-opening facts about the effects of noise pollution on obesity,”