Some poor data journalism here from the BBC on 28 May 2015, concerning turnover in professional soccer managers in England. “Managerial sackings reach highest level for 13 years” says the headline. A classic executive time series. What is the significance of the 13 years? Other than it being the last year with more sackings than the present.
The data was purportedly from the League Managers’ Association (LMA) and their Richard Bevan thought the matter “very concerning”. The BBC provided a chart (fair use claimed).

Now, I had a couple of thoughts as soon as I saw this. Firstly, why chart only back to 2005/6? More importantly, this looked to me like a stable system of trouble (for football managers) with the possible exception of this (2014/15) season’s Championship coach turnover. Personally, I detest multiple time series on a common chart unless there is a good reason for doing so. I do not think it the best way of showing variation and/ or association.
Signal and noise
The first task of any analyst looking at data is to seek to separate signal from noise. Nate Silver made this point powerfully in his book The Signal and the Noise: The Art and Science of Prediction. As Don Wheeler put it: all data has noise; some data has signal.
Noise is typically the irregular aggregate of many causes. It is predictable in the same way as a roulette wheel. A signal is a sign of some underlying factor that has had so large an effect that it stands out from the noise. Signals can herald a fundamental unpredictability of future behaviour.
If we find a signal we look for a special cause. If we start assigning special causes to observations that are simply noise then, at best, we spend money and effort to no effect and, at worst, we aggravate the situation.
The Championship data
In any event, I wanted to look at the data for myself. I was most interested in the Championship data as that was where the BBC and LMA had been quick to find a signal. I looked on the LMA’s website and this is the latest data I found. The data only records dismissals up to 31 March of the 2014/15 season. There were 16. The data in the report gives the total number of dismissals for each preceding season back to 2005/6. The report separates out “dismissals” from “resignations” but does not say exactly how the classification was made. It can be ambiguous. A manager may well resign because he feels his club have themselves repudiated his contract, a situation known in England as constructive dismissal.
The BBC’s analysis included dismissals right up to the end of each season including 2014/15. Reading from the chart they had 20. The BBC have added some data for 2014/15 that isn’t in the LMA report and not given the source. I regard that as poor data journalism.
I found one source of further data at website The Sack Race. That told me that since the end of March there had been four terminations.
| Manager | Club | Termination | Date |
| Malky Mackay | Wigan Athletic | Sacked | 6 April |
| Lee Clark | Blackpool | Resigned | 9 May |
| Neil Redfearn | Leeds United | Contract expired | 20 May |
| Steve McClaren | Derby County | Sacked | 25 May |
As far as I can tell, “dismissals” include contract non-renewals and terminations by mutual consent. There are then a further three dismissals, not four. However, Clark left Blackpool amid some corporate chaos. That is certainly a termination that is classifiable either way. In any event, I have taken the BBC figure at face value though I am alerted as to some possible data quality issues here.
Signal and noise
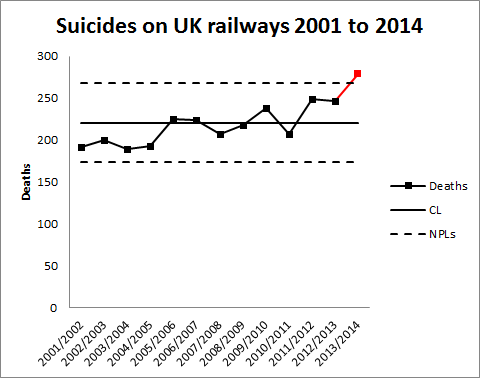
Looking at the Championship data, this was the process behaviour chart, plotted as an individuals chart.

There is a clear signal for the 2014/15 season with an observation, 20 dismissals,, above the upper natural process limit of 19.18 dismissals. Where there is a signal we should seek a special cause. There is no guarantee that we will find a special cause. Data limitations and bounded rationality are always constraints. In fact, there is no guarantee that there was a special cause. The signal could be a false positive. Such effects cannot be eliminated. However, signals efficiently direct our limited energy for, what Daniel Kahneman calls, System 2 thinking towards the most promising enquiries.
Analysis
The BBC reports one narrative woven round the data.
Bevan said the current tenure of those employed in the second tier was about eight months. And the demand to reach the top flight, where a new record £5.14bn TV deal is set to begin in 2016, had led to clubs hitting the “panic button” too quickly.
It is certainly a plausible view. I compiled a list of the dismissals and non-renewals, not the resignations, with data from Wikipedia and The Sack Race. I only identified 17 which again suggests some data quality issue around classification. I have then charted a scatter plot of date of dismissal against the club’s then league position.

It certainly looks as though risk of relegation is the major driver for dismissal. Aside from that, Watford dismissed Billy McKinlay after only two games when they were third in the league, equal on points with the top two. McKinlay had been an emergency appointment after Oscar Garcia had been compelled to resign through ill health. Watford thought they had quickly found a better manager in Slavisa Jokanovic. Watford ended the season in second place and were promoted to the Premiership.
There were two dismissals after the final game on 2 May by disappointed mid-table teams. Beyond that, the only evidence for impulsive managerial changes in pursuit of promotion is the three mid-season, mid-table dismissals.
| Club league position | |||
| Manager | Club | On dismissal | At end of season |
| Nigel Adkins | Reading | 16 | 19 |
| Bob Peeters | Charlton Athletic | 14 | 12 |
| Stuart Pearce | Nottingham Forrest | 12 | 14 |
A table that speaks for itself. I am not impressed by the argument that there has been the sort of increase in panic sackings that Bevan fears. Both Blackpool and Leeds experienced chaotic executive management which will have resulted in an enhanced force of mortality on their respective coaches. That along with the data quality issues and the technical matter I have described below lead me to feel that there was no great enhanced threat to the typical Championship manager in 2014/15.
Next season I would expect some regression to the mean with a lower number of dismissals. Not much of a prediction really but that’s what the data tells me. If Bevan tries to attribute that to the LMA’s activism them I fear that he will be indulging in Langian statistical analysis. Will he be able to resist?
Techie bit
I have a preference for individuals charts but I did also try plotting the data on an np-chart where I found no signal. It is trite service-course statistics that a Poisson distribution with mean λ has standard deviation √λ so an upper 3-sigma limit for a (homogeneous) Poisson process with mean 11.1 dismissals would be 21.1 dismissals. Kahneman has cogently highlighted how people tend to see patterns in data as signals even where they are typical of mere noise. In this case I am aware that the data is not atypical of a Poisson process so I am unsurprised that I failed to identify a special cause.
A Poisson process with mean 11.1 dismissals is a pretty good model going forwards and that is the basis I would press on any managers in contract negotiations.
Of course, the clubs should remember that when they look for a replacement manager they will then take a random sample from the pool of job seekers. Really!

.jpg#/media/File:Prince_George_of_Cambridge_with_wombat_plush_toy_(crop).jpg")