That was the headline in The Times (London) on 19 August 2013. The copy went on:
“Hundreds of young people have escaped death on Britain’s roads after laws were relaxed to allow pubs to open late into the night, a study has found.”
It was accompanied by a chart.

This conclusion was apparently based on a report detailing work led by Dr Colin Green at Lancaster University Management School. The report is not on the web but Lancaster were very kind in sending me a copy and I extend my thanks to them for the courtesy.
This is very difficult data to analyse. Any search for a signal has to be interpreted against a sustained fall in recorded accidents involving personal injury that goes back to the 1970s and is well illustrated in the lower part of the graphic (see here for data). The base accident data is therefore manifestly not stable and predictable. To draw inferences we need to be able to model the long term trend in a persuasive manner so that we can eliminate its influence and work with a residual data sequence amendable to statistical analysis.
It is important to note, however, that the authors had good reason to believe that relaxation of licensing laws may have an effect so this was a proper exercise in Confirmatory Data Analysis.
Reading the Lancaster report I learned that The Times graphic is composed of five-month moving averages. I do not think that I am attracted by that as a graphic. Shewhart’s Second Rule of Data Presentation is:
Whenever an average, range or histogram is used to summarise observations, the summary must not mislead the user into taking any action that the user would not take if the data were presented in context.
I fear that moving-averages will always obscure the message in the data. I preferred this chart from the Lancaster report. The upper series are for England, the lower for Scotland.
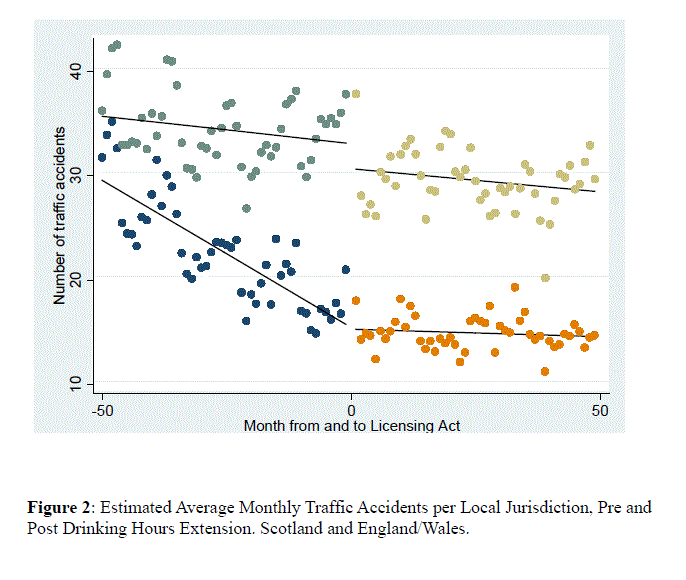
Now we can see the monthly observations. Subjectively there looks to be, at least in some years, some structure of variation throughout the year. That is unsurprising but it does ruin all hope of justifying an assumption of “independent identically distributed” residuals. Because of that alone, I feel that the use of p-values here is inappropriate, the usual criticisms of p-values in general notwithstanding (see the advocacy of Stephen Ziliak and Deirdre McCloskey).
As I said, this is very tricky data from which to separate signal and noise. Because of the patterned variation within any year I think that there is not much point in analysing other than annual aggregates. The analysis that I would have liked to have seen would have been a straight line regression through the whole of the annual data for England. There may be an initial disappointment that that gives us “less data to play with”. However, considering the correlation within the intra-year monthly figures, a little reflection confirms that there is very little sacrifice of real information. I’ve had a quick look at the annual aggregates for the period under investigation and I can’t see a signal. The analysis could be taken further by calculating an R2. That could then be compared with an R2 calculated for the Lancaster bi-linear “change point” model. Is the extra variation explained worth having for the extra parameters?
I see that the authors calculated an R2 of 42%. However, that includes accounting for the difference between English and Scottish data which is the dominant variation in the data set. I’m not sure what the Scottish data adds here other than to inflate R2.
There might also be an analysis approach by taking out the steady long term decline in injuries using a LOWESS curve then looking for a signal in the residuals.
What that really identifies are three ways of trying to cope with the long term declining trend, which is a nuisance in this analysis: straight line regression, straight line regression with “change point”, and LOWESS. If they don’t yield the same conclusions then any inference has to be treated with great caution. Inevitably, any signal is confounded with lack of stability and predictability in the long term trend.
I comment on this really to highlight the way the press use graphics without explaining what they mean. I intend no criticism of the Lancaster team as this is very difficult data to analyse. Of course, the most important conclusion is that there is no signal that the relaxation in licensing resulted in an increase in accidents. I trust that my alternative world view will be taken constructively.