In the words of the late, great Kenny Rogers, “There’ll be time enough for countin’/ When the dealin’s done”, but sometime, at the end of the Covid-19 crisis, somebody will ask How many died? and, more speculatively, how many deaths were avoidable.
There always seems an odd and uncomfortable premise at the base of that question, that somehow there is a natural or neutral, unmarked, control, null, default or proper, legitimate number who “should have” died, absent the virus. Yet that idea is challenged by our certain collective knowledge that, in living memory, there has been a persistent rise in life expectancy and longevity. Longevity has not stood still.
And I want to focus on that as it relates to a problem that has been bothering me for a while. It was brought into focus a few weeks ago by a headline in the Daily Mail, the UK’s house journal for health scares and faux consumer outrage.1
Life expectancy in England has ground to a halt for the first time in a century, according to a landmark report.
For context, I should say that this appeared 8 days after the UK government’s first Covid-19 press conference. Obviously, somebody had an idea about how much life expectancy should be increasing. There was some felt entitlement to an historic pattern of improvement that had been, they said, interrupted. It seems that the newspaper headline was based on a report by Sir Michael Marmot, Professor of Epidemiology and Public Health at University College London.2 This was Marmot’s headline chart.

Well, not quite the Daily Mail‘s “halt” but I think that there is no arguing with the chart. Despite there obviously having been some reprographic problem that has resulted in everything coming out in various shades of green and some gratuitous straight lines, it is clear that there was a break point around 2011. Following that, life expectancy has grown at a slower rate than before.
The chart did make me wonder though. The straight lines are almost too good to be true, like something from a freshman statistics service course. What happened in 2011? And what happened before 1980? Further, how is life expectancy for a baby born in 2018 being measured? I decided to go to the Office of National Statistics (UK) (“the ONS”) website and managed to find data back to 1841.
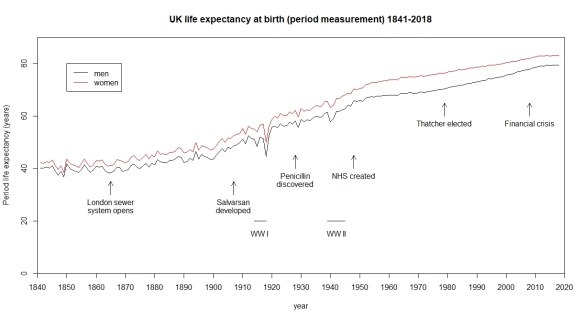
I have added some context but other narratives are available. Here is a different one.3
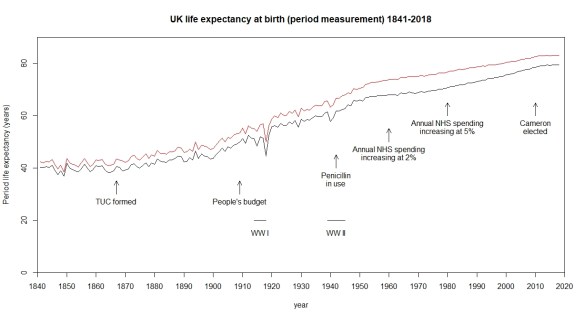
As Philip Tetlock4 and Daniel Kahneman5 have both pointed out, it is easy to find a narrative that fits both the data and our sympathies, and to use it as a basis for drawing conclusions about cause and effect. On the other hand, building a narrative is one of the most important components in understanding data. The way that data evolves over time and its linkage into an ecology of surrounding events is the very thing that drives our understanding of the cause system. Data has no meaning apart from its context. Knowledge of the cause system is critical to forecasting. But please use with care and continual trenchant criticism.
The first thing to notice from the chart is that there has been a relentless improvement in life expectancy over almost two centuries. However, it has not been uniform. There have been periods of relatively slow and relatively rapid growth. I could break the rate of improvement down into chunks as follows.
| Narrative |
From |
To |
Annual
increase in life
expectancy (yr) |
Standard
error (yr) |
| 1841 to opening of London Sewer |
1841 |
1865 |
-0.016 |
0.034 |
| London Sewer to Salvarsan |
1866 |
1907 |
0.192 |
0.013 |
| Salvarsan to penicillin |
1908 |
1928 |
0.458 |
0.085 |
| Penicillin to creation of NHS |
1929 |
1948 |
0.380 |
0.047 |
| NHS to Thatcher election |
1949 |
1979 |
0.132 |
0.007 |
| Thatcher to financial crisis |
1980 |
2008 |
0.251 |
0.004 |
| Financial crisis to 2018 |
2009 |
2018 |
0.122 |
0.022 |
Here I have rather crudely fitted a straight line to the period measurement (I am going to come back to what this means) for men over the various epochs to a get a feel for the pace of growth. It is a very rough and ready approach. However, it does reveal that the real periods of improvement of life expectancy were from 1908 to 1948, notoriously the period of two World Wards and an unmitigated worldwide depression.
Other narratives are available.
It does certainly look as though improvement has slowed since the financial crisis of 2008. However, it has only gone back to the typical rate between 1948 and 1979, a golden age for some people I think, and nowhere near the triumphal march of the first half of the twentieth century. We may as well ask why the years 1980 to 2008 failed to match the heroic era.
There are some real difficulties in trying to come to any conclusions about cause and effect from this data.
Understanding the ONS numbers
In statistics, life expectancy is fully characterised by the survivor function. Once we know that, we can calculate everything we need, in particular life expectancy (mean life). Any decent textbook on survival analysis tells you how to do this.6 The survivor function tells us the probability that an individual will survive beyond time t and die at some later unspecified date. Survivor functions look like this, in general.

It goes from t=0 until the chances of survival have vanished, steadily decreasing with moral certainty. In fact, you can extract life expectancy (mean life) from this by measuring the area under the curve, perhaps with a planimeter.
However, what we are talking about is a survivor function that changes over time. Not in the sense that a survivor function falls away as an individual ages. A man born in 1841 will have a particular survivor function. A man born in 2018 will have a better one. We have a sequence of generally improving survivor functions over the years.
Now you will see the difficulty in estimating the survivor function for a man born in 1980. Most of them are still alive and we have nil data on that cohort’s specific fatalities after 40 years of age. Now, there are statistical techniques for handling that but none that I am going to urge upon you. Techniques not without their important limitations but useful in the right context. The difficulty in establishing a survivor function for a newborn in 2020 is all the more problematic. We can look at the age of everyone who dies in a particular year, but that sample will be a mixture of men born in each and every year over the preceding century or so. The individual years’ survivor functions will be “smeared” out by the instantaneous age distribution of the UK, what in mathematical terms is called convolution. That helps us understand why the trends seem, in general, well behaved. What we are looking at is the aggregate of effects over the preceding decades. There will, importantly in the current context, be some “instantaneous” effects from epidemics and wars but those are isolated events within the general smooth trend of improvement.
There is no perfect solution to these problems. The ONS takes two approaches both of which it publishes.7 The first is just to regard the current distribution of ages at death as though it represented the survivor function for a person born this year. This, of course, is a pessimistic outlook for a newborn’s prospects. This year’s data is a mixture of the survivor functions for births over the last century or so, along with instantaneous effects. For much of those earlier decades, life expectancy was signally worse than it is now. However, the figure does give a conservative view and it does enable a year-on-year comparison of how we are doing. It captures instantaneous effects well. The ONS actually take the recorded deaths over the last three consecutive years. This is what they refer to as the period measurement and it is what I have used in this post.
The other method is slightly more speculative in that it attempts to reconstruct a “true” survivor function but is forced into making that through assuming an overall secular improvement in longevity. This is called the cohort measurement. The ONS use historical life data then assume that the annual rate of increase in life expectancy will be 1.2% from 2043 onwards. Rates between 2018 and 2043 are interpolated. The cohort measurement yields a substantially higher life expectancy than the period measurement, 87.8 years as against 79.5 years for 2018 male births.
Endogenous and exogenous improvement
Well, I really hesitated before I used those two economists’ terms but they are probably the most scholarly. I shall try to put it more cogently.
There is improvement contrived by endeavour. We identify some desired problem, conceive a plausible solution, implement, then measure the results against the pre-solution experience base. There are many established processes for this, DMAIC is a good one, but there is no reason to be dogmatic as to approach.
However, some improvement occurs because there is an environment of appropriate market conditions and financial incentives. It is the environment that is important in turning random, and possibly unmotivated, good ideas into improvement. As German sociologist Max Weber famously observed, “Ideas occur to us when they please, not when it pleases us.”8
For example, in 1858, engineer Joseph Bazalgette proposed an enclosed, underground sewer system for much of London. A causative association between fecal-contaminated water and cholera had been current since the work of John Snow in 1854. That’s another story. Bazalgette’s engineering was instrumental in relieving the city from cholera. That is an improvement procured by endeavour, endogenous if you like.
In 1928, Sir Alexander Fleming noticed how mould, accidentally contaminating his biological samples, seemed to inhibit bacterial growth. Fleming pursued this random observation and ended up isolating penicillin. However, it took a broader environment of value, demand and capital to launch penicillin as a pharmaceutical product, some time in the 1940s. There were critical stages of clinical trials and industrial engineering demanding significant capital investment and constancy of purpose. Howard Florey, Baron Florey, was instrumental and, in many ways, his contribution is greater than Fleming’s. However, penicillin would not have reached the public had the market conditions not been there. The aggregate of incremental improvements arising from accidents of discovery, nurtured by favourable external economic and political forces, are the exogenous improvements. All the partisans will claim success for their party.
Of course, it is, to some extent, a fuzzy characterisation. Penicillin required Florey’s (endogenous) endeavour. All endeavour takes place within some broader (exogenous) culture of improvement. Paul Ehrlich hypothesised that screening an array of compounds could identify drugs with anti-bacterial properties. Salvarsan’s effectiveness against syphilis was discovered as part of such a programme and then developed and marketed as a product by Hoechst in 1910. An interaction of endogenous and exogenous forces.
It is, for business people who know their analytics, relatively straightforward to identify improvements from endogenous endeavour. But where they dynamics are exogenous, economists can debate and politicians celebrate or dispute. Improvements can variously be claimed on behalf of labour law, state aid, nationalisation, privatisation or market deregulation. Then, is the whole question of cause and effect slightly less obvious than we think? Moderns carol the innovation of penicillin. We shudder noting that, in 1924, a US President’s son died simply because of an infection originating in an ill-fitting tennis shoe.9 However, looking at the charts of life expectancy, there is no signal from the introduction of penicillin, I think. What caused that improvement in the first half of the twentieth century?
Cause and effect
It was philosopher-scientist-lawyer Francis Bacon who famously observed:
It were infinite for the law to judge the causes of causes and the impression one on another.
We lawyers are constantly involved in disputes over cause and effect. We start off by accepting that nearly everything that happens is as a result of many causes. Everyday causation is inevitably a multifactorial matter. That is why the cause and effect diagram is essential to any analysis, in law, commerce or engineering. However, lawyers are usually concerned with proving that a particular factor caused an outcome. Other factors there may be and that may well be a matter of contribution from other parties but liability turns on establishing that a particular action was part of the causative nexus.
The common law has some rather blunt ways of dealing with the matter. Pre-eminent is the “but for” test. We say that A caused B if B would not have happened but for A. There may well have been other causes of B, even ones that were more important, but it is A that is under examination. That though leaves us with, at least, a couple of problems. Lord Hoffman pointed out the first problem in South Australia Asset Management Corporation Respondents v York Montague Ltd.10
A mountaineer about to take a difficult climb is concerned about the fitness of his knee. He goes to the doctor who makes a superficial examination and pronounces the knee fit. The climber goes on the expedition, which he would not have undertaken if the doctor told him the true state of his knee. He suffers an injury which is an entirely foreseeable consequence of mountaineering but has nothing to do with his knee.
The law deals with this by various devices: operative cause, remoteness and foreseeability, reasonable foreseeability, reasonable contemplation of the parties, breaks in the chain of causation, boundaries on the duty of care … . The law has to draw a line and avoid “opening the floodgates” of liability.11, 12 How the line can be drawn objectively in social science is a different matter.
The second issue was illustrated in a fine analysis by Prof. David Spiegelhalter as to headlines of 40,000 annual UK deaths because of air pollution.13 Daily Mail again! That number had been based on historical longitudinal observational studies showing greater force of mortality among those with greater exposure to particular pollutants. I presume, though Spiegelhalter does not go into this in terms, that there is some plausible physio-chemical cause system that can describe the mechanism of action of inhaled chemicals on metabolism and the risk of early death.
Thus we can expose a population to a risk with a moral certainty that more will die than absent the risk. That does not, of itself, enable us to attribute any particular death to the exposure. There may, in any event, be substantial uncertainty about the exact level of risk.
The law is emphatic. Mere exposure to a risk is insufficient to establish causation and liability.14 There are a few exceptions. I will not go into them here. The law is willing to find causation in situations that fall short of but for where it finds that the was a material contribution to a loss.15 However, a claimant must, in general, show a physical route to the individual loss or injury.16
A question of attribution
Thus, even for those with Covid-19 on their death certificate, the cause will typically be multi-factorial. Some would have died in the instant year in any event. And some others will die because medical resources have been diverted from the quotidian treatment of the systemic perils of life. The local disruption, isolation, avoidance and confinement may well turn out to result in further deaths. Domestic violence is a salient repercussion of this pandemic.
But there is something beyond that. One of Marmot’s principle conclusions was that the recent pause in improvement of life expectancy was the result of poverty. In general, the richer a community becomes, the longer it lives. Poverty is a real factor in early death. On 14 April 2020, the UK Office of Budget Responsibility opined that the UK economy could shrink by 35% by June.17 There was likely to be a long lasting impact on public finances. Such a contraction would dwarf even the financial crisis of 2008. If the 2008 crisis diminished longevity, what will a Covid-19 depression do? How will deaths then be attributed to the virus?
The audit of Covid-19 deaths is destined to be controversial, ideological, partisan and likely bitter. The data, once that has been argued over, will bear many narratives. There is no “right” answer to this. An honest analysis will embrace multiple accounts and diverse perspectives. We live in hope.
I think it was Jack Welch who said that anybody could manage the short term and anybody could manage the long term. What he needed were people who could manage the short term and the long term at the same time.
References
- “Life expectancy grinds to a halt in England for the first time in 100 YEARS”, Daily Mail , 25/2/20, retrieved 13/4/20
- Marmot, M et al. (2020) Health Equity in England: The Marmot Review 10 Years On, Institute of Health Equity
- NHS expenditure data from, “How funding for the NHS in the UK has changed over a rolling ten year period”, The Health Foundation, 31/10/15, retrieved 14/4/20
- Tetlock, P & Gardner, D (2015) Superforecasting: The Art and Science of Prediction, Random House
- Kahneman, D (2011) Thinking, fast and slow, Allen Lane
- Mann, N R et al. (1974) Methods for Statistical Analysis of Reliability and Life Data, Wiley
- “Period and cohort life expectancy explained”, ONS, December 2019, retrieved 13/4/20
- Weber, M (1922) “Science as a vocation”, in Gessamelte Aufsätze zur Wissenschaftslehre, Tubingen, JCB Mohr 1922, 524-555
- The medical context of Calvin Jr’s untimely death“, Coolidge Foundation, accessed 13/4/20
- [1997] AC 191 at 213
- Charlesworth & Percy on Negligence, 14th ed., 2-03
- Lamb v Camden LBC [1981] QB 625, per Lord Denning at 636
- “Does air pollution kill 40,000 people each year in the UK?”, D Siepgelhalter, Medium, 20/2/17, retrieved 13/4/20
- Wilsher v Essex Area Health Authority [1988] AC 1075, HL
- Bailey v Ministry of Defence [2008] EWCA Civ 883, [2009] 1 WLR 1052
- Pickford v ICI [1998] 1 WLR 1189, HL
- “Coronavirus: UK economy ‘could shrink by record 35%’ by June”, BBC News 14/4/20, retrieved 14/4/20


 So why?
So why? 



