
 I had an intriguing insight into the nature of imagination the other evening when I was watching David Eagleman’s BBC documentary The Brain which you can catch on iPlayer until 27 February 2016 if you have a UK IP address.
I had an intriguing insight into the nature of imagination the other evening when I was watching David Eagleman’s BBC documentary The Brain which you can catch on iPlayer until 27 February 2016 if you have a UK IP address.
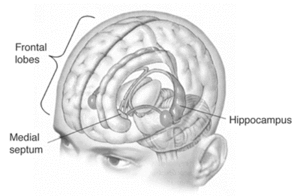
Eagleman told the strange story of Henry Molaison. Molaison suffered from debilitating epilepsy following a bicycle accident when he was nine years old. At age 27, Molaison underwent radical brain surgery that removed, all but completely, his hippocampi. The intervention stabilised the epilepsy but left Molaison’s memory severely impaired. Though he could recall his childhood, Molaison had no recall of events in the years leading up to his surgery and was unable to create new long-term memories. The case was important evidence for the theory that the hippocampus is critical to memory function. Molaison, having lost his, was profoundly compromised as to recall.
But Eagleman’s analysis went further and drew attention to a passage in a interview with Molaison later in his life.1 Though his presenting symptoms post-intervention were those of memory loss, Molaison also encountered difficulty in talking about what he would do the following day. Eagleman advances the theory that the hippocampus is critical, not only to memory, but to imagining the future. The systems that create memories are common to those that generate a model by which we can forecast, predict and envision novel outcomes.
I blogged about imagination back in November and how it was pivotal to core business activities from invention and creativity to risk management and root cause analysis. If Eagleman’s theory about the entanglement of memory and imagination is true then it might have profound implications for management. Perhaps our imagination will only function as well as our memory. That was, apparently, the case with Molaison. It could just be that an organisation’s ability to manage the future depends upon the same systems as those by which it critically captures the past.
That chimes with a theory of innovation put forward by W Brian Arthur of the Santa Fe Institute.2 Arthur argues that purportedly novel inventions are no more than combinations of known facts. There are no great leaps of creativity, just the incremental variation of a menagerie of artifacts and established technologies. Ideas similar to Arthur’s have been advanced by Matt Ridley,3,4 and Steven Berlin Johnson.5 Only mastery of the present exposes the opportunities to innovate. They say.
Data
This all should be no surprise to anybody experienced in business improvement. Diligent and rigorous criticism of historical data is the catalyst of change and the foundation of realising a vivid future. This is a good moment to remind ourselves of the power of the process behaviour chart in capturing learning and creating an organisational memory.

The process behaviour chart provides a cogent record of the history of operation of a business process, its surprises and disappointments, existential risks and epochs of systematic productivity. It records attempted business solutions, successful, failed, temporary and partial work-rounds. It segregates signal from noise. It suggests realistic bounds on prediction. It is the focus of inclusive discussion about what the data means. It is the live report of experimentation and investigation, root cause analysis and problem solving. It matches data with its historical context. It is the organisation’s memory of development of a business process, and the people who developed it. It is the basis for creating the future.
If you are not familiar with how process behaviour charts work in this context then have a look at Don Wheeler’s example of A Japanese Control Chart.6
Leadership
Tim Harford tries to take the matter further.7 On Harford’s account of invention, “trial and error” consistently outperform “expert leadership” through a Darwinian struggle of competing ideas. The successful innovations, Harford says, propagate by adoption and form an ecology of further random variation, out of which the best ideas emergently repeat the cycle or birth and death. Of course, Leo Tolstoy wrote War and Peace, his “airport novel” avant la lettre, (also currently being dramatised by the BBC) to support exactly this theory of history. In Tolsoy’s intimate descriptions of the Battles of Austerlitz and Borodino, combatants lose contact with their superiors, battlefields are obscured by smoke from the commanding generals, individuals act on impulse and in despite of field discipline. How, Tolstoy asked in terms, could anyone claim to be the organising intelligence of victory or the culpable author of defeat?
However, I think that a view of war at odds with Tolstoy’s is found in the career of General George Marshall.8 Marshall rose to the rank of General of the Army of the USA as an expert in military logistics rather than as a commander in the field. Reading a biography of Marshall presents an account of war as a contest of supply chains. The events of the theatre of operations may well be arbitrary and capricious. It was the delivery of superior personnel and materiel to the battlefield that would prove decisive. That does not occur without organisation and systematic leadership. I think.
Harford and the others argue that, even were the individual missing from history, the innovation would still have occurred. But even though it could have been anyone, it still had to be someone. And what that someone had to provide was leadership to bring the idea to market or into operation. We would still have motor cars without Henry Ford and tablet devices without Steve Jobs but there would have been two other names who had put themselves on the line to create something out of nothing.
In my view, the evolutionary model of innovation is interesting but stretches a metaphor too far. Innovation demands leadership. The history of barbed wire is instructive.9 In May 1873, at a county fair in Illinois, Henry B Rose displayed a comical device to prevent cattle beating down primitive fencing, a “wooden strip with metallic points”. The device hung round the cattle’s horns and any attempts to butt the fence drove the spikes into the beast’s head. It didn’t catch on but at the fair that day were Joseph Glidden, Isaac L Ellwood and Jacob Haish. The three went on, within a few months, each to invent barbed wire. The winning memes often come from failed innovation.
Leadership is critical, not only in scrutinising innovation but in organising the logistics that will bring it to market.10 More fundamentally, leadership is pivotal in creating the organisation in which diligent criticism of historical data is routine and where it acts as a catalyst for innovation.11
References
- http://www.sciencemuseum.org.uk/visitmuseum_OLD/galleries/who_am_i/~/media/8A897264B5064BC7BE1D5476CFCE50C5.ashx, retrieved 29 January 2016, at p5
- Arthur, W B (2009) The Nature of Technology: What it is and How it Evolves, The Free Press/ Penguin Books.
- Ridley, M (2010) The Rational Optimist, Fourth Estate
- — (2015) The Evolution of Everything, Fourth Estate
- Johnson, S B (2010) Where Good Ideas Come From: The Seven Patterns of Innovation, Penguin
- Wheeler, D J (1992) Understanding Statistical Process Control, SPC Press
- Harford, T (2011) Adapt: Why Success Always Starts with Failure, Abacus
- Cray, E (2000) General of the Army: George C. Marshall, Soldier and Statesman, Cooper Square Press
- Krell, A (2002) The Devil’s Rope: A Cultural History of Barbed Wire, Reaktion Books
- Armytage, W H G (1976) A Social History of Engineering, 4th ed., Faber
- Nonaka, I & Takeuchi, H (1995) The Knowledge-Creating Company: How Japanese Companies Create the Dynamics of Innovation, Oxford University Press

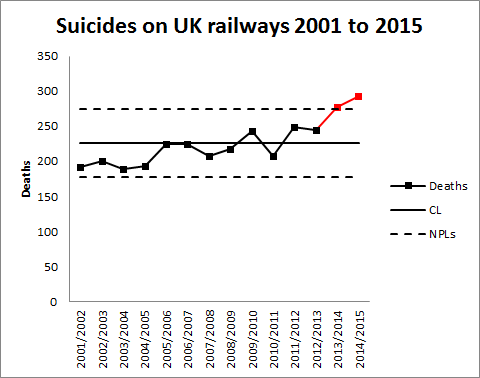
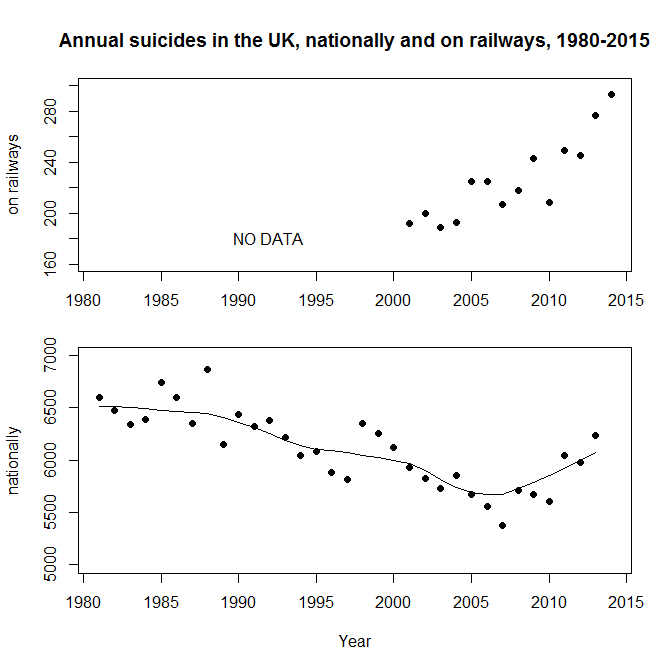
 I started my grown-up working life on a project seeking to predict extreme ocean currents off the north west coast of the UK. As a result I follow environmental disasters very closely. I fear that it’s natural that incidents in my own country have particular salience. I don’t want to minimise disasters elsewhere in the world when I talk about
I started my grown-up working life on a project seeking to predict extreme ocean currents off the north west coast of the UK. As a result I follow environmental disasters very closely. I fear that it’s natural that incidents in my own country have particular salience. I don’t want to minimise disasters elsewhere in the world when I talk about 

