
It’s taken me a while to sit down and blog about this news item from October 2014: Sharp Rise in Railway Suicides Say Network Rail . Regular readers of this blog will know that I have followed this data series closely in 2013 and 2012.
The headline was based on the latest UK government data. However, I baulk at the way these things are reported by the press. The news item states as follows.
The number of people who have committed suicide on Britain’s railways in the last year has almost reached 300, Network Rail and the Samaritans have warned. Official figures for 2013-14 show there have already been 279 suicides on the UK’s rail network – the highest number on record and up from 246 in the previous year.
I don’t think it’s helpful to characterise 279 deaths as “almost … 300”, where there is, in any event, no particular significance in the number 300. It arbitrarily conveys the impression that some pivotal threshold is threatened. Further, there is no especial significance in an increase from 246 to 279 deaths. Another executive time series. Every one of the 279 is a tragedy as is every one of the 246. The experience base has varied from year to year and there is no surprise that it has varied again. To assess the tone of the news report I have replotted the data myself.
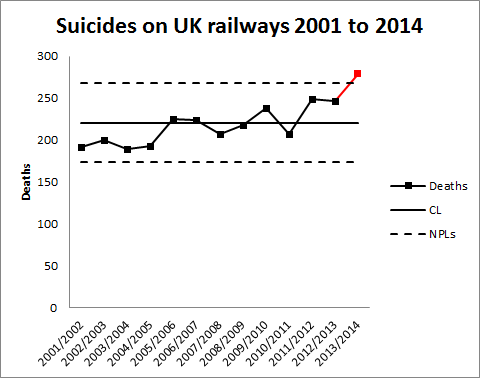
Readers should note the following about the chart.
- Some of the numbers for earlier years have been updated by the statistical authority.
- I have recalculated natural process limits as there are still no more than 20 annual observations.
- There is now a signal (in red) of an observation above the upper natural process limit.
The news report is justified, unlike the earlier ones. There is a signal in the chart and an objective basis for concluding that there is more than just a stable system of trouble. There is a signal and not just noise.
As my colleague Terry Weight always taught me, a signal gives us license to interpret the ups and downs on the chart. There are two possible narratives that immediately suggest themselves from the chart.
- A sudden increase in deaths in 2013/14; or
- A gradual increasing trend from around 200 in 2001/02.
The chart supports either story. To distinguish would require other sources of information, possibly historical data that can provide some borrowing strength, or a plan for future data collection. Once there is a signal, it makes sense to ask what was its cause. Building a narrative around the data is a critical part of that enquiry. A manager needs to seek the cause of the signal so that he or she can take action to improve system outcomes. Reliably identifying a cause requires trenchant criticism of historical data.
My first thought here was to wonder whether the railway data simply reflected an increasing trend in suicide in general. Certainly a very quick look at the data here suggests that the broader trend of suicides has been downwards and certainly not increasing. It appears that there is some factor localised to railways at work.
I have seen proposals to repeat a strategy from Japan of bathing railway platforms with blue light. I have not scrutinised the Japanese data but the claims made in this paper and this are impressive in terms of purported incident reduction. If these modifications are implemented at British stations we can look at the chart to see whether there is a signal of fewer suicides. That is the only real evidence that counts.
Those who were advocating a narrative of increasing railway suicides in earlier years may feel vindicated. However, until this latest evidence there was no signal on the chart. There is always competition for resources and directing effort on a false assumptions leads to misallocation. Intervening in a stable system of trouble, a system featuring only noise, on the false belief that there is a signal will usually make the situation worse. Failing to listen to the voice of the process on the chart risks diverting vital resources and using them to make outcomes worse.
Of course, data in terms of time between incidents is much more powerful in spotting an early signal. I have not had the opportunity to look at such data but it would have provided more, better and earlier evidence.
Where there is a perception of a trend there will always be an instinctive temptation to fit a straight line through the data. I always ask myself why this should help in identifying the causes of the signal. In terms of analysis at this stage I cannot see how it would help. However, when we come to look for a signal of improvement in future years it may well be a helpful step.



 Smart investigators know that the provenance, reliability and quality of data cannot be taken for granted but must be subject to appropriate scrutiny. The modern science of
Smart investigators know that the provenance, reliability and quality of data cannot be taken for granted but must be subject to appropriate scrutiny. The modern science of 
