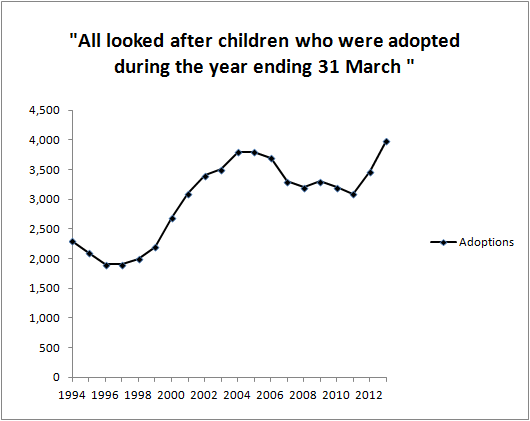
3. Cease dependence on inspection to achieve quality. Eliminate the need for massive inspection by building quality into the product in the first place.
 Point 3 of Deming’s 14 Points. This at least cannot be controversial. For me it goes to the heart of Deming’s thinking.
Point 3 of Deming’s 14 Points. This at least cannot be controversial. For me it goes to the heart of Deming’s thinking.
The point is that every defective item produced (or defective service delivered) has taken cash from the pockets of customers or shareholders. They should be more angry. One day they will be. Inputs have been purchased with their cash, their resources have been deployed to transform the inputs and they will get nothing back in return. They will even face the costs of disposing of the scrap, especially if it is environmentally noxious.
That you have an efficient system for segregating non-conforming from conforming is unimpressive. That you spend even more of other people’s money reworking the product ought to be a matter of shame. Lean Six Sigma practitioners often talk of the hidden factory where the rework takes place. A factory hidden out of embarrassment. The costs remain whether you recognise them or not. Segregation is still more problematic in service industries.
The insight is not unique to Deming. This is a common theme in Lean, Six Sigma, Theory of Constraints and other approaches to operational excellence. However, Deming elucidated the profound statistical truths that belie the superficial effectiveness of inspection.
Inspection is inefficient
When I used to work in the railway industry I was once asked to look at what percentage of signalling scheme designs needed to be rechecked to defend against the danger of a logical error creeping through. The problem requires a simple application of Bayes’ theorem. I was rather taken aback at the result. There were only two strategies that made sense: recheck everything or recheck nothing. I didn’t at that point realise that this is a standard statistical result in inspection theory. For a wide class of real world situations, where the objective is to segregate non-conforming from conforming, the only sensible sampling schemes are 100% or 0%.
Where the inspection technique is destructive, such as a weld strength test, there really is only one option.
Inspection is ineffective
All inspection methods are imperfect. There will be false-positives and false-negatives. You will spend some money scrapping product you could have sold for cash. Some defective product will escape onto the market. Can you think of any examples in your own experience? Further, some of the conforming product will be only marginally conforming. It won’t delight the customer.
So build quality into the product
… and the process for producing the product (or delivering the service). Deming was a champion of the engineering philosophy of Genechi Taguchi who put forward a three-stage approach for achieving, what he called, off-line quality control.
- System design – in developing a product (or process) concept think about how variation in inputs and environment will affect performance. Choose concepts that are robust against sources of variation that are difficult or costly to control.
- Parameter design – choose product dimensions and process settings that minimise the sensitivity of performance to variation.
- Tolerance design – work out the residual sources of variation to which performance remains sensitive. Develop control plans for measuring, managing and continually reducing such variation.
Is there now no need to measure?
Conventional inspection aimed at approving or condemning a completed batch of output. The only thing of interest was the product and whether it conformed. Action would be taken on the batch. Deming called the application of statistics to such problems an enumerative study.
But the thing managers really need to know about is future outcomes and how they will be influenced by present decisions. There is no way of sampling the future. So sampling of the past has to go beyond mere characterisation and quantification of the outcomes. You are stuck with those and will have to take the consequences one way or another. Sampling (of the past) has to aim principally at understanding the causes of those historic outcomes. Only that enables managers to take a view on whether those causes will persist in the future, in what way they might change and how they might be adjusted. This is what Deming called an analytic study.
Essential to the ability to project data into the future is the recognition of common and special causes of variation. Only when managers are confident in thinking and speaking in those terms will their organisations have a sound basis for action. Then it becomes apparent that the results of inspection represent the occult interaction of inherent variation with threshold effects. Inspection obscures the distinction between common and special causes. It seduces the unwary into misguided action that exacerbates quality problems and reputational damage. It obscures the sad truth that, as Terry Weight put it, a disappointment is not necessarily a surprise.
The programme
- Drive out sensitivity to variation at the design stage.
- Routinely measure the inputs whose variation threatens product performance.
- Measure product performance too. Your bounded rationality may have led you to get (2) wrong.
- No need to measure every unit. We are trying to understand the cause system not segregate items.
- Plot data on a process behaviour chart.
- Stabilise the system.
- Establish capability.
- Keep on measuring to maintain stability and improve capability.
Some people think they have absorbed Deming’s thinking, mastered it even. Yet the test is the extent to which they are able to analyse problems in terms of common and special causes of variation. Is that the language that their organisation uses to communicate exceptions and business performance, and to share analytics, plans, successes and failures?
There has always been some distaste for Deming’s thinking among those who consider it cold, statistically driven and paralysed by data. But the data are only a means to getting beyond the emotional reaction to those two impostors: triumph and disaster. The language of common and special causes is a profound tool for building engagement, fostering communication and sharing understanding. Above that, it is the only sound approach to business measurement.