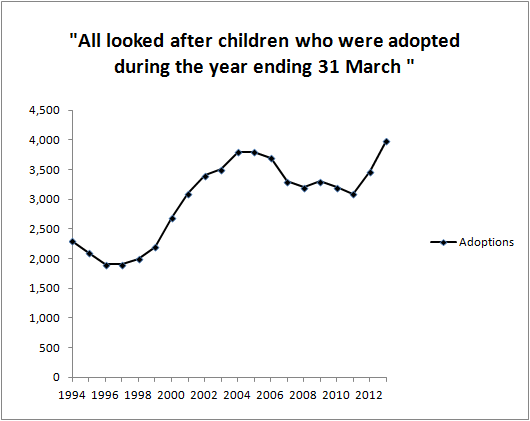
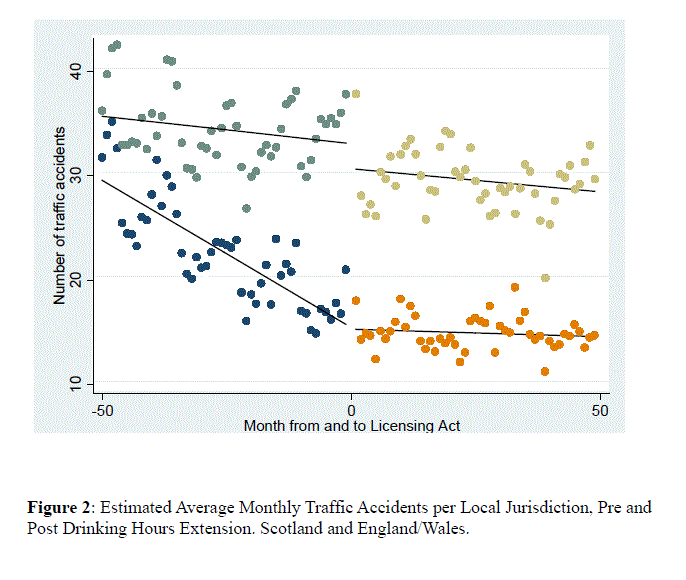
Today (20 November 2013) I was reading an item in The Times (London) with the headline “We fiddle our crime numbers, admit police”. This is a fairly unedifying business.
The blame is once again laid at the door of government targets and performance related pay. I fear that this is akin to blaming police corruption on the largesse of criminals. If only organised crime would stop offering bribes, the police would not succumb to taking them in consideration of repudiating their office as constable, so the argument might run (pace Brian Joiner). Of course, the argument is nonsense. What we expect of police constables is honesty even, perhaps especially, when temptation presents itself. We expect the police to give truthful evidence in court, to deal with the public fairly and to conduct their investigations diligently and rationally. The public expects the police to behave in this way even in the face of manifest temptation to do otherwise. The public expects the same honest approach to reporting their performance. I think Robert Frank put it well in Passions within Reason.
The honest individual … is someone who values trustworthiness for its own sake. That he might receive a material payoff for such behaviour is beyond his concern. And it is precisely because he has this attitude that he can be trusted in situations where his behaviour cannot be monitored. Trustworthiness, provided it is recognizable, creates valuable opportunities that would not otherwise be available.
Matt Ridley put it starkly in his overview of evolutionary psychology, The Origins of Virtue. He wasn’t speaking of policing in particular.
The virtuous are virtuous for no other reason that it enables them to join forces with others who are virtuous, for mutual benefit.
What worried me most about the article was a remark from Peter Barron, a former detective chief superintendent in the Metropolitan Police. Should any individual challenge the distortion of data:
You are judged to be not a team player.
“Teamwork” can be a smokescreen for the most appalling bullying. In our current corporate cultures, to be branded as “not a team player” can be the most horrible slur, smearing the individual’s contribution to the overall mission. One can see how such an environment can allow a team’s behaviours and objectives to become misaligned from those of the parent organisation. That is a problem that can often be addressed by management with a proper system of goal deployment.
However, the problem is more severe when the team is in fact well aligned to what are distorted organisational goals. The remedies for this lie in the twin processes of governance and whistleblowing. Neither seem to be working very well in UK policing at the moment but that simply leaves an opportunity for process improvement. Work is underway. The English law of whistleblowing has been amended this year. If you aren’t familiar with it you can find it here.
Governance has to take scrutiny of data seriously. Reported performance needs to be compared with other sources of data. Reporting and recording processes need themselves to be assessed. Where there is no coherent picture questions need to be asked.